

How To Train And Test Data In Python
Machine Learning - Train/Test
Evaluate Your Model
In Automobile Learning we create models to predict the event of certain events, like in the previous chapter where we predicted the CO2 emission of a car when we knew the weight and engine size.
To measure if the model is good enough, nosotros tin can apply a method called Train/Test.
What is Railroad train/Test
Train/Test is a method to measure the accuracy of your model.
It is chosen Train/Test because you split the the data set up into ii sets: a training set and a testing set.
lxxx% for preparation, and 20% for testing.
You lot train the model using the training set up.
Yous test the model using the testing fix.
Train the model means create the model.
Test the model means exam the accuracy of the model.
Offset With a Data Set
Beginning with a data set you want to test.
Our data fix illustrates 100 customers in a shop, and their shopping habits.
Case
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, ane, 100)
y = numpy.random.normal(150, 40, 100) / ten
plt.scatter(x, y)
plt.show()
Result:
The x axis represents the number of minutes before making a purchase.
The y centrality represents the amount of money spent on the purchase.
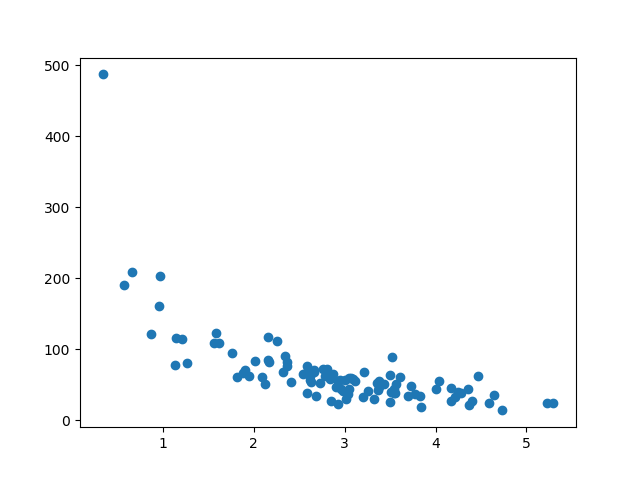
Run example »
Divide Into Train/Test
The training set should be a random selection of 80% of the original data.
The testing set should exist the remaining 20%.
test_x = 10[80:]train_x = x[:80]
train_y = y[:lxxx]
test_y = y[80:]
Display the Preparation Set
Display the aforementioned besprinkle plot with the preparation set:
Instance
plt.scatter(train_x, train_y)
plt.show()
Result:
It looks like the original information set up, so it seems to exist a off-white selection:
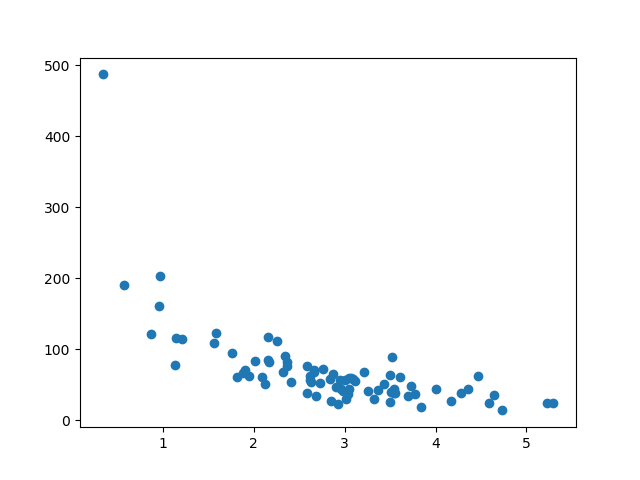
Run instance »
Display the Testing Fix
To make sure the testing fix is non completely different, we will take a look at the testing set also.
Example
plt.scatter(test_x, test_y)
plt.show()
Upshot:
The testing set as well looks like the original data prepare:
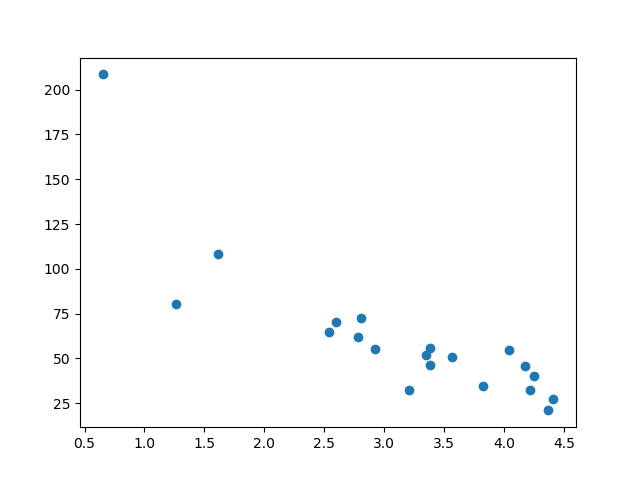
Run example »
Fit the Data Set
What does the information set look like? In my opinion I think the best fit would be a polynomial regression, so let us describe a line of polynomial regression.
To draw a line through the information points, we utilise the plot() method of the matplotlib module:
Example
Draw a polynomial regression line through the data points:
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(two)
x = numpy.random.normal(3, one, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = 10[:80]
train_y = y[:lxxx]
test_x = x[80:]
test_y = y[80:]
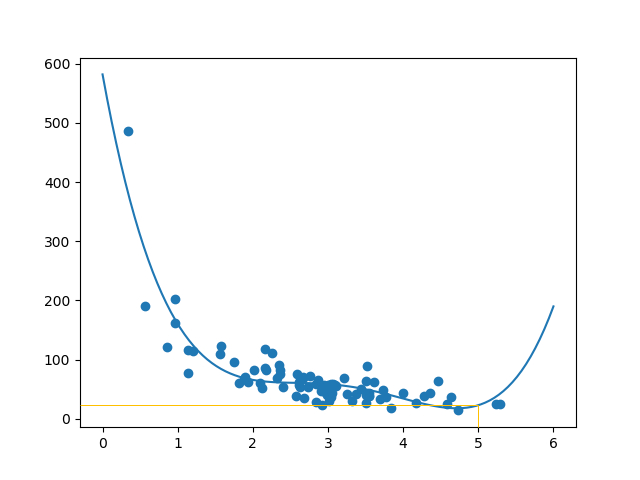
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
myline = numpy.linspace(0, 6, 100)
plt.scatter(train_x, train_y)
plt.plot(myline, mymodel(myline))
plt.show()
Event:
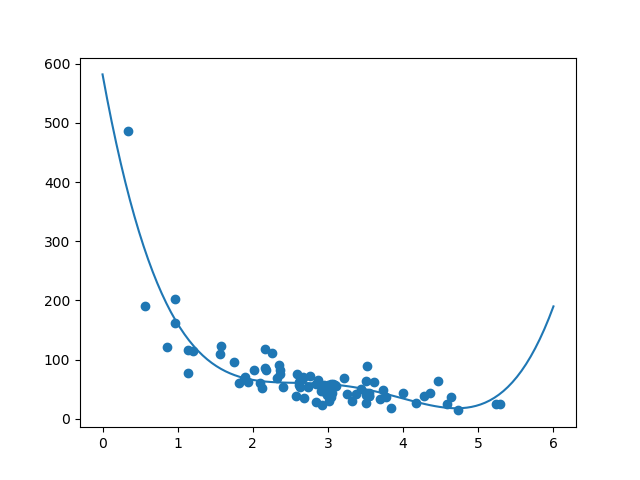
Run example »
The result tin back my suggestion of the data set fitting a polynomial regression, even though it would requite us some weird results if we try to predict values outside of the data gear up. Example: the line indicates that a customer spending 6 minutes in the store would make a buy worth 200. That is probably a sign of overfitting.
But what about the R-squared score? The R-squared score is a skilful indicator of how well my data set up is fitting the model.
R2
Call back R2, also known as R-squared?
Information technology measures the relationship between the x axis and the y centrality, and the value ranges from 0 to 1, where 0 means no relationship, and 1 means totally related.
The sklearn module has a method chosen r2_score() that will assistance us find this relationship.
In this case we would like to measure the relationship between the minutes a customer stays in the shop and how much money they spend.
Example
How well does my training data fit in a polynomial regression?
import numpy
from sklearn.metrics import r2_score
numpy.random.seed(ii)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / ten
train_x = ten[:80]
train_y = y[:fourscore]
test_x = 10[80:]
test_y = y[lxxx:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, iv))
r2 = r2_score(train_y, mymodel(train_x))
print(r2)
Attempt information technology Yourself »
Notation: The result 0.799 shows that there is a OK relationship.
Bring in the Testing Set
Now we have made a model that is OK, at least when it comes to training data.
Now we desire to test the model with the testing data as well, to see if gives united states the aforementioned result.
Example
Let us find the R2 score when using testing data:
import numpy
from sklearn.metrics import r2_score
numpy.random.seed(2)
x = numpy.random.normal(three, ane, 100)
y = numpy.random.normal(150, twoscore, 100) / x
train_x = x[:fourscore]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
r2 = r2_score(test_y, mymodel(test_x))
print(r2)
Effort it Yourself »
Notation: The result 0.809 shows that the model fits the testing prepare likewise, and we are confident that we can apply the model to predict future values.
Predict Values
Now that we accept established that our model is OK, we can start predicting new values.
Example
How much money will a buying customer spend, if she or he stays in the shop for 5 minutes?
print(mymodel(5))
Run example »
The example predicted the client to spend 22.88 dollars, as seems to correspond to the diagram:

How To Train And Test Data In Python,
Source: https://www.w3schools.com/python/python_ml_train_test.asp
Posted by: grangerwhatedou.blogspot.com
0 Response to "How To Train And Test Data In Python"
Post a Comment